在Python中,模型训练的暂停通常是通过设置断点或者使用特定的库来实现的,这里我们主要介绍两种方法:使用断点和使用tensorflow库的Checkpoint。
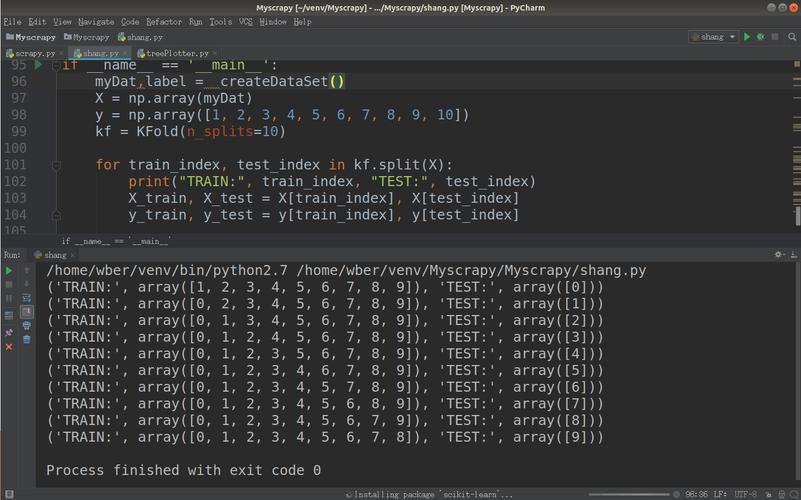
1、使用断点
在Python中,我们可以使用pdb库来设置断点。pdb是Python的一个内置调试器,可以帮助我们在代码执行过程中暂停,查看变量值,单步执行等。
我们需要在需要暂停的地方添加断点,我们有一个训练函数train_model,我们希望在每100轮迭代后暂停,可以这样设置断点:
def train_model(data, labels):
for i in range(1000):
# 训练模型的代码...
# 每100轮迭代后暂停
if i % 100 == 0:
import pdb; pdb.set_trace()
我们可以通过命令行启动Python解释器,并附加到我们的脚本上:
python m pdb train_model.py
接下来,我们可以在命令行中输入各种调试命令,
n(next):执行下一行代码
s(step):进入函数内部
c(continue):继续执行,直到遇到下一个断点或程序结束
q(quit):退出调试器,终止程序运行
2、使用tensorflow库的Checkpoint
另一种方法是使用tensorflow库的Checkpoint。Checkpoint可以帮助我们在模型训练过程中保存模型的权重,以便在需要时恢复训练,这样,我们可以在训练过程中定期保存模型,然后在恢复训练时选择暂停的时间点。
我们需要导入所需的库:
import tensorflow as tf
我们可以在训练函数中使用tf.train.Checkpoint来保存模型:
def train_model(data, labels):
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
checkpoint.restore(tf.train.latest_checkpoint('./checkpoints')).expect_partial()
for i in range(1000):
# 训练模型的代码...
# 每100轮迭代后保存模型
if i % 100 == 0:
checkpoint.save('./checkpoints/model.ckpt')
接下来,我们可以在需要恢复训练时选择暂停的时间点,我们希望从第200轮迭代开始恢复训练,可以这样操作:
def resume_training(data, labels):
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
checkpoint.restore(tf.train.latest_checkpoint('./checkpoints')).expect_partial()
# 从第200轮迭代开始恢复训练
for i in range(200, 1000):
# 训练模型的代码...
通过以上两种方法,我们可以实现在Python模型训练过程中的暂停,需要注意的是,这些方法仅适用于单机训练,对于分布式训练或其他复杂的训练场景,可能需要采用其他方法来实现暂停。
```



评论留言